




Running A Chatgpt-like Llm On The Raspberry Pi 5

Made by shakhizat / Artificial intelligence
About the project
Discover how to run an advanced ChatGPT-Like large language models on the Raspberry Pi 5
Project info
Difficulty: Difficult
Platforms: Raspberry Pi, Elecrow
Estimated time: 3 hours
License: GNU General Public License, version 3 or later (GPL3+)
Items used in this project
Hardware components
Story
In this tutorial, I will demonstrate how to run a large language model on a brand-new Raspberry Pi 5, a low-cost and portable computer that can fit in your pocket.
However, it's important to note that running a large language model on a Raspberry Pi comes with some challenges and limitations. The full versions of the models are too big and complex for the Raspberry Pi's hardware, so you'll need to use smaller and simpler versions, such as quantized models, which have fewer parameters and layers but still retain most of the capabilities of the original models.
Here's a picture of my recent Raspberry Pi 5 from Elecrow:

If you're interested in keeping your Raspberry Pi cool while running heavy-loaded large language models, consider purchasing a Raspberry Pi Active Cooler.

This mini fan keeps the Pi cool and quiet, even while tackling heavy workloads, which is essential for optimal performance and longevity.
Here's my setup, as pictured below:
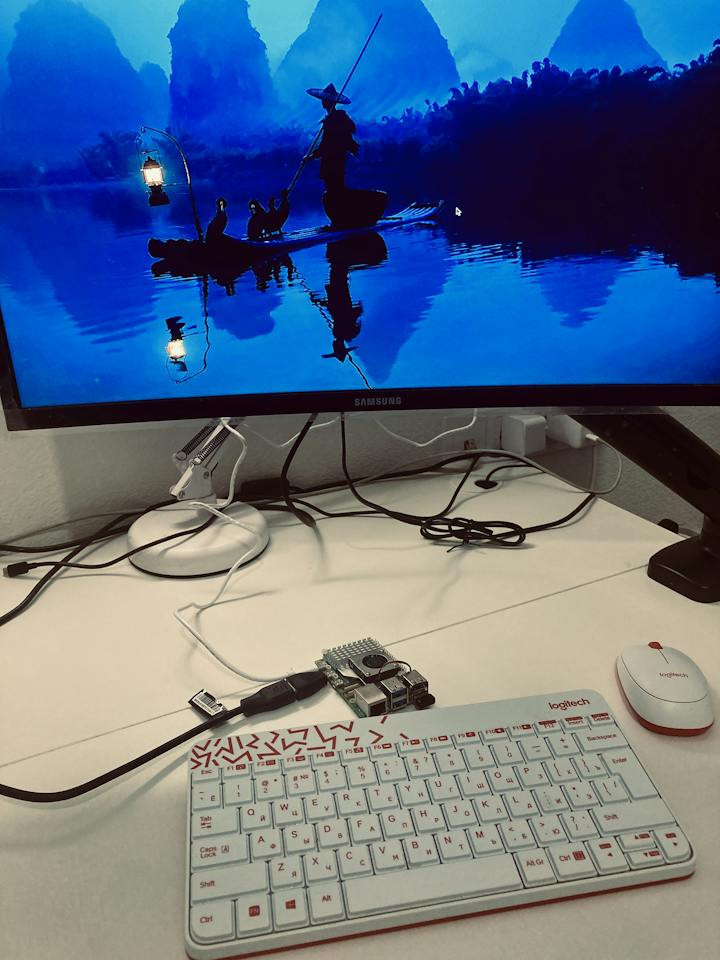
Now, let's dive into the delightful details of downloading and running these powerful large language models right on our Raspberry Pi 5!
Inference using Llama.cpp
The gold standard of local-only model inference for LLMs is LLaMA-cpp, developed by Georgi Gerganov. No dependencies, no GPU needed, just point it to a model snapshot that you download separately.
Clone the Llama.cpp repository
git clone https://github.com/ggerganov/llama.cppNext, navigate to the cloned directory using the cd command:
cd llama.cppNow, compile the code using the make command:
makeI downloaded the quantized Microsoft phi-2 model weight from the Hugging Face repository. Phi-2 is an excellent choice for running LLMs tasks on the Raspberry Pi. When running the larger models, make sure you have enough disk space. To avoid any errors, please make sure to download only the .gguf model files before running the mode.
Execute the following command to run it:
./main -m ./phi-2.Q4_K_M.gguf --color
-c 2048 --temp 0.7 --repeat_penalty 1.1 -n -1 -i --n-predict -2
-p "please tell me who is robert oppenheimer:"If it is operating correctly, the following prompt will appear.
Robert Oppenheimer was an American theoretical physicist, best known for his work on the Manhattan Project during World War II. He was also a professor at the University of California, Berkeley and played a key role in the development of the atomic bomb.
>
llama_print_timings: load time = 736.10 ms
llama_print_timings: sample time = 152.55 ms / 53 runs ( 2.88 ms per token, 347.43 tokens per second)
llama_print_timings: prompt eval time = 1605.74 ms / 20 tokens ( 80.29 ms per token, 12.46 tokens per second)
llama_print_timings: eval time = 10321.61 ms / 53 runs ( 194.75 ms per token, 5.13 tokens per second)
llama_print_timings: total time = 56993.36 ms / 73 tokensResult is 5 tokens/sec.
LLaMA-cpp supports various LLMs, including Mistral 7B Instruct v0.2. Replace./path/to/model.gguf with the actual path to your downloaded model file.
./main -m ./mistral-7b-instruct-v0.2.Q4_K_M.gguf --color
-c 2048 --temp 0.7 --repeat_penalty 1.1 -n -1 -i --n-predict -2
-p "please tell me who is robert oppenheimer:"Example output with Mistral 7B Instruct v0.2:
please tell me who is robert oppenheimer: Robert Oppenheimer (April 22, 1904 – February 18, 1967) was an American physicist and leader in the development of the atomic bomb during World War II. He is often referred to as the "Father of the Atomic Bomb" for his role in managing the Los Alamos Laboratory where the weapon was designed and built. After the war, he became a leading scientific advisor to the US government on nuclear weapons and international disarmament. However, his security clearance was revoked after allegations of Communist ties, ending his career in science.
llama_print_timings: load time = 741.32 ms
llama_print_timings: sample time = 32.26 ms / 131 runs ( 0.25 ms per token, 4060.88 tokens per second)
llama_print_timings: prompt eval time = 2105.43 ms / 12 tokens ( 175.45 ms per token, 5.70 tokens per second)
llama_print_timings: eval time = 56629.44 ms / 131 runs ( 432.29 ms per token, 2.31 tokens per second)
llama_print_timings: total time = 114989.98 ms / 143 tokensResult is 2 tokens/sec.
Inference using Ollama
Ollama provides a more user-friendly way to get LLMs running on your local machine. To get started, download the Ollama CLI and install it using the following command:
curl https://ollama.ai/install.sh | shThe output will be:
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0>>> Downloading ollama...
100 8422 0 8422 0 0 13497 0 --:--:-- --:--:-- --:--:-- 13518
######################################################################## 100.0%######################################################################### 100.0%
>>> Installing ollama to /usr/local/bin...
>>> Creating ollama user...
>>> Adding ollama user to render group...
>>> Adding current user to ollama group...
>>> Creating ollama systemd service...
>>> Enabling and starting ollama service...
Created symlink /etc/systemd/system/default.target.wants/ollama.service → /etc/systemd/system/ollama.service.
>>> The Ollama API is now available at 0.0.0.0:11434.
>>> Install complete. Run "ollama" from the command line.
WARNING: No NVIDIA GPU detected. Ollama will run in CPU-only mode.If no GPU is detected, Ollama will run in CPU-only mode, which may impact speed.
Then, run the following command to download and run Microsoft Phi-2:
ollama run phi --verboseYou should see output similar to the following:
pulling manifest
pulling 04778965089b... 100% ▕████████████████▏ 1.6 GB
pulling 7908abcab772... 100% ▕████████████████▏ 1.0 KB
pulling 774a15e6f1e5... 100% ▕████████████████▏ 77 B
pulling 3188becd6bae... 100% ▕████████████████▏ 132 B
pulling 0b8127ddf5ee... 100% ▕████████████████▏ 42 B
pulling 4ce4b16d33a3... 100% ▕████████████████▏ 555 B
verifying sha256 digest
writing manifest
removing any unused layers
success
>>> please tell me who is robert oppenheimer
Robert Oppenheimer was a renowned physicist, academician, and military scientist who played a
key role in the development of the atomic bomb during World War II. He is widely known for his
work on the Manhattan Project, where he served as the director of the Los Alamos National
Laboratory. After the war, he became involved in the scientific community and was instrumental
in creating the field of nuclear physics. Oppenheimer's research contributed significantly to
our understanding of the atom and its potential applications, including nuclear energy and
medicine.
total duration: 25.58233235s
load duration: 606.444µs
prompt eval duration: 522.659ms
prompt eval rate: 0.00 tokens/s
eval count: 105 token(s)
eval duration: 25.057718s
eval rate: 4.19 tokens/sThis will download the model and provide output regarding the download progress. You can then interact with the model by typing prompts and receiving responses.
You can also run the same command but for Mistral model:
ollama run mistral --verboseThe output will be:
Robert Oppenheimer was an American theoretical physicist and professor of physics at the
University of California, Berkeley. He is best known for his role in the Manhattan Project
during World War II, where he led the team that designed and built the atomic bombs used by the
United States against the cities of Hiroshima and Nagasaki. The development of the atomic bomb
is considered to be one of the greatest scientific achievements of the 20th century. After the
war, Oppenheimer became the first director of the Los Alamos National Laboratory in New Mexico
and later served as the chairman of the General Advisory Committee of the United States Atomic
Energy Commission. In the late 1940s and early 1950s, however, Oppenheimer fell out of favor
with the U.S. government due to his political views and was eventually stripped of his security
clearance. He continued to work in physics but was never able to regain the prominence he had
enjoyed before.
total duration: 2m8.905908665s
load duration: 504.04µs
prompt eval count: 20 token(s)
prompt eval duration: 10.248923s
prompt eval rate: 1.95 tokens/s
eval count: 207 token(s)
eval duration: 1m58.655013s
eval rate: 1.74 tokens/sNote that larger models generally have slower output speeds. For example, Phi-2 (2.7B parameters) generates around 4 tokens per second, while Mistral (7B parameters) produces around 2 tokens per second.
I hope you found this project useful and thanks for reading. If you have any questions or feedback? Leave a comment below.
References:Credits
Related products


























g