

Revealing The Potential Of Mycobot Ai Kit Vision Algorithms
Made by Elephant Robotics / Robotics
About the project
In this article, we will delve deeper into understanding how the machine recognition algorithm of myCobot 320 AI Kit is implemented.
Project info
Difficulty: Easy
Platforms: M5Stack, Elephant Robotics
Estimated time: 1 hour
License: GNU General Public License, version 3 or later (GPL3+)
Items used in this project
Hardware components

Software apps and online services
Story
In this article, we will delve deeper into understanding how the machine recognition algorithm of myCobot 320 AI Kit is implemented. In today's society, with the continuous development of artificial intelligence technology, the application of robotic arms is becoming increasingly widespread. As a robot that can simulate human arm movements, the robotic arm has a series of advantages such as efficiency, precision, flexibility, and safety. In industrial, logistics, medical, agricultural and other fields, robotic arms have become an essential part of many automated production lines and systems. For example, in scenes such as automated assembly on factory production lines, cargo handling in warehouse logistics, auxiliary operations in medical surgery, and planting and harvesting in agricultural production, robotic arms can play its unique role. This article will focus on introducing the application of robotic arms combined with vision recognition technology in the myCobot 320 AI Kit scene, and exploring the advantages and future development trends of robotic arm vision control technology.
ProductmyCobot 320myCobot 320 is a 6-axis collaborative robot designed for user-independent programming and development. With a motion radius of 350mm, it can support a maximum end load of 1000g with a repetitive positioning accuracy of 0.5mm. It provides a fully open software control interface that enables users to quickly control the robotic arm using a variety of mainstream programming languages.

1 / 2


The myCobot adaptive gripper is an end-of-arm actuator used for grasping and transporting objects of various shapes and sizes. It has high flexibility and adaptability and can automatically adjust its gripping force and position based on the shape and size of different objects. It can be combined with machine vision to adjust the gripping force and position of the gripper by obtaining information from vision algorithms. The gripper can handle objects up to 1kg and has a maximum grip distance of 90mm. It is powered by electricity and is very convenient to use. This is the equipment we are using, along with the myCobot 320 AI Kit that we will be using later.
Vision algorithmVision algorithm is a method of analyzing and understanding images and videos using computer image processing techniques. It mainly includes several aspects such as image preprocessing, feature extraction, object detection, and pose estimation.
Image preprocessing:
Image preprocessing is the process of processing the original image to make it more suitable for subsequent analysis and processing. Commonly used algorithms include image denoising algorithms, image enhancement algorithms, and image segmentation algorithms.
Feature point extraction:
Feature extraction is the process of extracting key features from the image for further analysis and processing. Common algorithms include SIFT algorithm, SURF algorithm, ORB algorithm, HOG algorithm, LBP algorithm, etc.
Object detection:
Object detection is the process of finding a specific object or target in an image. Commonly used algorithms include Haar feature classifier, HOG feature + SVM classifier, Faster R-CNN, YOLO.
Pose estimation:
Pose estimation is the process of estimating the pose of an object by identifying its position, angle, and other information. Common algorithms include PnP algorithm, EPnP algorithm, Iterative Closest Point algorithm (ICP), etc.
ExampleColor recognition algorithm
The verbiage is too abstract. Let us demonstrate this step through practical application. How can we detect the white golf ball in the image below? We shall employ the use of OpenCV's machine vision library.

Image processing:
Initially, we must preprocess the image to enable the computer to swiftly locate the target object. This step involves converting the image to grayscale.
A grayscale image is a method of converting a colored image to a black and white image. It depicts the brightness or gray level of each pixel in the image. In a grayscale image, the value of each pixel represents its brightness, typically ranging from 0 to 255, where 0 represents black and 255 represents white. The intermediate values represent varying degrees of grayness.
import cv2
import numpy as np
image = cv2.imread('ball.jpg')
# turn to gray pic
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
cv2.imshow('gray', gray)Gray image

Gray image
Binarization:
As we can observe, there is a significant color contrast between the golf ball and the background in the image. We can detect the target object through color detection. Although the golf ball is primarily white, there are some gray shadow areas caused by lighting. Therefore, while setting the pixels of the grayscale image, we must consider the gray areas as well.
lower_white = np.array([180, 180, 180]) # Lower limit
upper_white = np.array([255, 255, 255]) # Upper limit
# find target object
mask = cv2.inRange(image, lower_white, upper_white)
contours, _ = cv2.findContours(mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)This step is called binarization, which separates the target object from the background.
Contour filtering:
After binarization, we need to establish a filter for the contour area size. If we fail to set this filter, we may encounter the result depicted in the image below, where many areas are selected, whereas we only desire the largest one. By filtering out small regions, we can achieve our desired outcome.

#filter
min_area = 100
filtered_contours = [cnt for cnt in contours if cv2.contourArea(cnt) > min_area]
#draw border
for cnt in filtered_contours:
x, y, w, h = cv2.boundingRect(cnt)
cv2.rectangle(image, (x, y), (x+w, y+h), (0, 0, 255), 2)
Code:
import cv2
import numpy as np
image = cv2.imread('ball.jpg')
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
lower_white = np.array([170, 170, 170])
upper_white = np.array([255, 255, 255])
mask = cv2.inRange(image, lower_white, upper_white)
contours, _ = cv2.findContours(mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
min_area = 500
filtered_contours = [cnt for cnt in contours if cv2.contourArea(cnt) > min_area]
for cnt in filtered_contours:
x, y, w, h = cv2.boundingRect(cnt)
cv2.rectangle(image, (x, y), (x+w, y+h), (0, 0, 255), 2)
cv2.imshow('Object Detection', image)
cv2.waitKey(0)
cv2.destroyAllWindows()It is important to note that we are utilizing a robotic arm to grasp the object. Hence, merely detecting the target object is insufficient. We must obtain the coordinate information of the object. To achieve this, we use OpenCV's Aruco markers, which are commonly used 2D barcodes for tasks such as camera calibration, pose estimation, and camera tracking in computer vision. Each Aruco marker has a unique identifier. By detecting and recognizing these markers, we can infer the position of the camera and the relationship between the camera and the markers.


The two unique Arcuo codes in the picture are used to fix the size of the cropped picture and the position of the arcuo code, and the target object can be obtained through calculation.
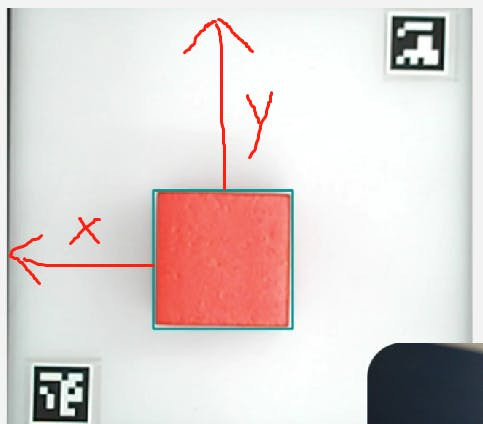
With the Aruco marker's positioning, we can detect the location of the target object. We can then convert the x and y coordinates into world coordinates and provide them to the robotic arm's coordinate system. The robotic arm can then proceed with grasping the object.

Part of the code
# get points of two aruco
def get_calculate_params(self, img):
"""
Get the center coordinates of two ArUco codes in the image
:param img: Image, in color image format.
:return: If two ArUco codes are detected, returns the coordinates of the centers of the two codes; otherwise returns None.
"""
# Convert the image to a gray image
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# Detect ArUco marker.
corners, ids, rejectImaPoint = cv2.aruco.detectMarkers(
gray, self.aruco_dict, parameters=self.aruco_params
)
"""
Two Arucos must be present in the picture and in the same order.
There are two Arucos in the Corners, and each aruco contains the pixels of its four corners.
Determine the center of the aruco by the four corners of the aruco.
"""
if len(corners) > 0:
if ids is not None:
if len(corners) <= 1 or ids[0] == 1:
return None
x1 = x2 = y1 = y2 = 0
point_11, point_21, point_31, point_41 = corners[0][0]
x1, y1 = int((point_11[0] + point_21[0] + point_31[0] + point_41[0]) / 4.0), int(
(point_11[1] + point_21[1] + point_31[1] + point_41[1]) / 4.0)
point_1, point_2, point_3, point_4 = corners[1][0]
x2, y2 = int((point_1[0] + point_2[0] + point_3[0] + point_4[0]) / 4.0), int(
(point_1[1] + point_2[1] + point_3[1] + point_4[1]) / 4.0)
return x1, x2, y1, y2
return None
# set camera clipping parameters
def set_cut_params(self, x1, y1, x2, y2):
self.x1 = int(x1)
self.y1 = int(y1)
self.x2 = int(x2)
self.y2 = int(y2)
# set parameters to calculate the coords between cube and mycobot320
def set_params(self, c_x, c_y, ratio):
self.c_x = c_x
self.c_y = c_y
self.ratio = 320.0 / ratio
# calculate the coords between cube and mycobot320
def get_position(self, x, y):
return ((y - self.c_y) * self.ratio + self.camera_x), ((x - self.c_x) * self.ratio + self.camera_y)The key difference between the YOLO algorithm and OpenCV algorithm lies in the fact that YOLOv5 is a deep learning-based object detection algorithm, unlike OpenCV's traditional computer vision methods. Although OpenCV offers object detection functionality, it mainly relies on traditional image processing and computer vision techniques. YOLOv5, on the other hand, is a deep learning model based on neural networks, where the network learns through continuous training to recognize objects in images by identifying patterns and features.
A neural network is like a human brain, constantly receiving knowledge from the outside world, learning to differentiate between an apple and a strawberry. By continuously training and providing different images of apples and strawberries, the network is able to recognize and accurately locate these objects in an image.

Code
# detect object
def post_process(self, input_image):
class_ids = []
confidences = []
boxes = []
blob = cv2.dnn.blobFromImage(input_image, 1 / 255, (self.INPUT_HEIGHT, self.INPUT_WIDTH), [0, 0, 0], 1,
crop=False)
# Sets the input to the network.
self.net.setInput(blob)
# Run the forward pass to get output of the output layers.
outputs = self.net.forward(self.net.getUnconnectedOutLayersNames())
rows = outputs[0].shape[1]
image_height, image_width = input_image.shape[:2]
x_factor = image_width / self.INPUT_WIDTH
y_factor = image_height / self.INPUT_HEIGHT
cx = 0
cy = 0
try:
for r in range(rows):
row = outputs[0][0][r]
confidence = row[4]
if confidence > self.CONFIDENCE_THRESHOLD:
classes_scores = row[5:]
class_id = np.argmax(classes_scores)
if (classes_scores[class_id] > self.SCORE_THRESHOLD):
confidences.append(confidence)
class_ids.append(class_id)
cx, cy, w, h = row[0], row[1], row[2], row[3]
left = int((cx - w / 2) * x_factor)
top = int((cy - h / 2) * y_factor)
width = int(w * x_factor)
height = int(h * y_factor)
box = np.array([left, top, width, height])
boxes.append(box)
'''Non-maximum suppression to obtain a standard box'''
indices = cv2.dnn.NMSBoxes(boxes, confidences, self.CONFIDENCE_THRESHOLD, self.NMS_THRESHOLD)
for i in indices:
box = boxes[i]
left = box[0]
top = box[1]
width = box[2]
height = box[3]
cv2.rectangle(input_image, (left, top), (left + width, top + height), self.BLUE,
3 * self.THICKNESS)
cx = left + (width) // 2
cy = top + (height) // 2
cv2.circle(input_image, (cx, cy), 5, self.BLUE, 10)
label = "{}:{:.2f}".format(self.classes[class_ids[i]], confidences[i])
# draw real_sx, real_sy, detect.color)
self.draw_label(input_image, label, left, top)
# cv2.imshow("nput_frame",input_image)
# return input_image
except Exception as e:
print(e)
exit(0)
if cx + cy > 0:
return cx, cy, input_image
else:
return None
YOLO developers provide open source code on GitHub. If you have special needs, you can set the training method yourself to achieve the effect.
Apart from YOLOv5, there are other algorithms such as shape recognition, feature point detection, and 2D barcode recognition. These functionalities are all integrated into the myCobot 320 AI Kit.
myCobot 320 AI KitThis is an AI kit designed for the myCobot 320 robotic arm, which integrates the aforementioned vision algorithms with the robotic arm. The myCobot 320 robotic arm is equipped with an adaptive gripper and suction cup at its end effector, enabling it to grasp or suction objects.
Identify watermelons and grab them

Identify watermelons and grab them
Identify the red wooden block and suck it up

Identify the red wooden block and suck it up
This kit is an excellent beginners‘ package for those interested in learning artificial intelligence, computer vision algorithms, and the principles of robotic arms. The kit is open-source, and all the code is provided for learning purposes.
If you want to know more about the introduction and operation of myCobot 320 AI Kit, here is an article to the myCobot 320 AI Kitthat was published before.
SummaryIf you have superior ideas regarding artificial intelligence suites, you have the complete freedom to craft a personalized application scenario for your own robotic arm, utilizing AI Kit as the foundation, and boldly exhibit your concepts.
Vision-based control technology for robotic arms is a rapidly developing and widely applied technology. Compared to traditional robotic arm control technology, vision-based control technology boasts advantages such as high efficiency, precision, and flexibility, and can be extensively utilized in industrial production, manufacturing, logistics, and other fields. With the constant evolution of technology such as artificial intelligence and machine learning, vision-based control technology for robotic arms will have even wider application scenarios. In the future, it will be necessary to strengthen technological research and development and innovation, constantly improving the level of technology and application capabilities.
Credits
Elephant Robotics
Elephant Robotics is a technology firm specializing in the design and production of robotics, development and applications of operating system and intelligent manufacturing services in industry, commerce, education, scientific research, home and etc.
Related products











Leave your feedback...